
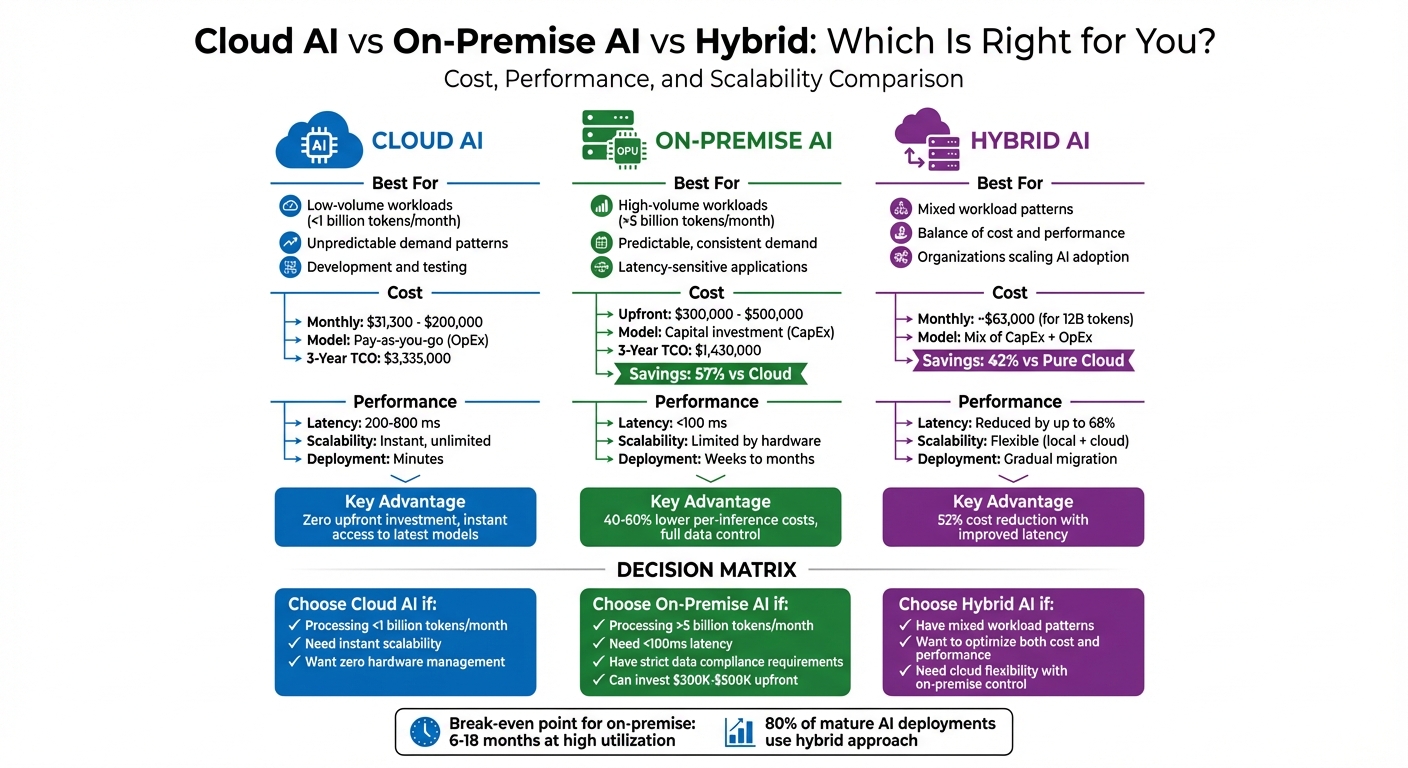
Choosing between Cloud AI and On-Premise AI depends on your workload, budget, and performance needs. Here’s a quick breakdown:
- Cloud AI: Ideal for flexibility and low upfront costs. Great for workloads under 1 billion tokens/month or unpredictable demand. Costs range from $31,300 to $200,000 per month for 10 billion tokens. Latency is higher (200–800 ms), but scalability is instant.
- On-Premise AI: Best for consistent, high-volume workloads (over 5 billion tokens/month). Requires large initial investments ($300,000–$500,000 for an 8× NVIDIA H100 cluster) but offers long-term savings (40–60% lower per-inference costs). Latency is lower (<100 ms), making it suitable for real-time applications.
- Hybrid Approach: Combines both for cost efficiency and performance. Handle predictable tasks on-premise and use the cloud for surges or new projects. Can reduce costs by up to 52% while improving latency.
Quick Comparison:
| Factor | Cloud AI | On-Premise AI | Hybrid AI |
|---|---|---|---|
| Cost | $31,300–$200,000/month | $300,000–$500,000 upfront | Mix of cloud and on-prem |
| Latency | 200–800 ms | <100 ms | Improves with local routing |
| Scalability | Instant | Limited by hardware | Flexible |
| Best For | Low-volume, unpredictable | High-volume, predictable | Balanced workloads |
For businesses processing over 1 billion tokens/month, consider a detailed cost analysis to determine the best fit. Cloud AI offers flexibility, while on-premise delivers better long-term savings and performance.
Cloud AI vs On-Premise AI vs Hybrid: Cost, Latency, and Scalability Comparison
Cloud Vs. On-Prem for Generative AI Systems
Cost Comparison: Cloud AI vs On-Premise AI
Understanding the total cost of ownership (TCO) for both cloud and on-premise AI models is crucial when deciding which option suits your workload. Cloud AI operates on an operational expense (OpEx) model, requiring minimal upfront investment but ongoing usage-based costs. On the other hand, on-premise AI involves significant upfront capital expenditure (CapEx) but can lead to long-term savings for workloads that are both high-volume and predictable.
Cloud AI Cost Breakdown
Cloud AI follows a pay-as-you-go pricing structure. For example, processing 10 billion tokens per month can cost anywhere from $31,300 (Google Gemini 1.5 Pro) to $200,000 (OpenAI GPT-4 Turbo). This model’s biggest advantage is its flexibility – companies only pay for what they use, avoiding the need for expensive hardware purchases.
However, additional costs can quickly add up. These include data egress fees ranging from $0.05 to $0.12 per GB, logging and monitoring expenses between $0.50 and $3.00 per GB, API rate limit upgrades, and cross-region replication. Together, these can increase baseline compute costs by 15% to 30%. For instance, a computer vision system with 10,000 cameras might incur about $7,740 per month in data transfer fees alone.
Specialized roles like FinOps and API integration engineers are also required to manage cloud deployments, with annual salaries in the range of $150,000 to $200,000. To cut costs, organizations can utilize 1- to 3-year reserved instance commitments or spot pricing for non-critical workloads, saving between 30% and 60%.
On-Premise AI Cost Breakdown
Unlike the flexible costs of cloud AI, on-premise AI involves a significant upfront investment but offers predictable operating expenses over time. For example, an 8× NVIDIA H100 GPU cluster costs between $300,000 and $500,000, with GPU prices expected to decline by 15% to 20% annually.
Operational expenses primarily include power and cooling costs. An 8× H100 cluster, drawing about 10 kW of power, incurs an annual electricity cost of roughly $8,700 (assuming a rate of $0.10/kWh). Including cooling, total operational costs range from $35,000 to $50,000 per year. Additional expenses include data center space or colocation fees ($500 to $2,000 per month per rack) and maintenance contracts (10–15% of hardware costs annually).
Staffing costs for on-premise setups are also a factor, with salaries averaging $180,000 per year for ML infrastructure engineers and $60,000 per year for DevOps support. Moreover, hardware utilization rates typically hover around 40% to 60%, lower than the 80% to 90% often assumed. Planning for around 60% utilization provides a more accurate return on investment (ROI).
One real-world example highlights the potential savings: In Q3 2025, a healthcare system handling 15 billion tokens per month transitioned from cloud APIs costing $1.62 million annually to an on-premise cluster with 24× A100 GPUs. With an initial investment of $420,000 and annual operating costs of $380,000, the organization saved $828,000 annually, achieving a payback period of just 7 months.
3-Year Cost Comparison Table
For workloads processing 10 billion tokens per month, the cost difference between cloud and on-premise AI becomes striking over three years:
| Year | Cloud AI (Claude 3.5 Sonnet) | On-Premise (16× A100 GPUs) |
|---|---|---|
| Year 1 | $1,150,000 | $639,000 |
| Year 2 | $1,090,000 | $359,000 |
| Year 3 | $1,095,000 | $432,000 |
| Total 3-Year TCO | $3,335,000 | $1,430,000 |
| Total Savings | – | $1,905,000 (57%) |
This table illustrates that on-premise AI can lower the 3-year TCO by 57% for organizations with steady, high-volume workloads. For systems with high utilization, the break-even point typically occurs within 6 to 18 months. Businesses processing more than 1 billion tokens per month should consider conducting a detailed TCO analysis to assess the feasibility of migrating to on-premise infrastructure.
These cost considerations lay the groundwork for exploring the performance differences between cloud and on-premise AI solutions.
Performance Comparison: Cloud AI vs On-Premise AI
When it comes to AI deployment, performance is just as critical as cost. The choice between cloud and on-premise AI can directly impact whether your application meets user expectations – especially for latency-sensitive tasks like fraud detection, medical imaging, or real-time robotics, where every millisecond matters.
Latency and Real-Time Processing
On-premise AI typically outperforms cloud-based APIs in latency, delivering 2× to 5× faster response times. While cloud AI often incurs 200–800 ms latency due to network and processing overhead, on-premise setups equipped with GPUs like the NVIDIA H100 can achieve sub-100 ms latency for models such as Llama 3.1 70B.
Take the example of a European logistics company. In Q3 2025, they adopted a hybrid setup with 18 NVIDIA Jetson AGX Orin units for real-time package sorting. By shifting 70% of inference tasks to the edge, they slashed latency from 220 ms (on AWS SageMaker) to just 70 ms. This 68% improvement boosted package processing rates by 18%. Similarly, a digital payments platform handling $2 billion monthly reduced fraud detection latency from 280 ms to 85 ms by prioritizing high-risk transactions on on-premise NVIDIA T4 GPUs. The result? An 81% cost reduction and a 15% improvement in fraud detection accuracy.
For applications demanding response times under 100 ms – think surgical robots, high-frequency trading systems, or autonomous vehicles – on-premise AI often remains the only practical solution. Meanwhile, cloud AI is better suited for tasks where higher latencies (200 ms or more) are acceptable, such as chatbots, content creation, or batch processing.
With latency covered, let’s dive into scalability and throughput.
Scalability and Throughput
Cloud AI shines in scalability, offering the ability to deploy thousands of GPUs within minutes. For example, AWS UltraClusters can allocate over 512 GPUs for large-scale training or inference tasks, making cloud solutions ideal for workloads with unpredictable or fluctuating demands.
On the other hand, on-premise AI delivers consistent, high throughput for stable workloads by avoiding network bottlenecks and provider rate limits. A single NVIDIA H100, for instance, can process about 80 tokens per second for Llama 3.1 70B, scaling up to 280 tokens per second with a 4× H100 setup. For businesses with consistent, high-volume needs, this reliability – combined with lower latency – can outweigh the flexibility of cloud scaling.
"Cloud GPUs scale in real time, though performance depends on network bandwidth and load."
- Jess Lulka, DigitalOcean
The trade-off is clear: cloud AI provides virtually unlimited scalability, but performance can fluctuate due to network conditions and shared resources. On-premise AI, in contrast, offers predictable, consistent performance, although it’s limited by physical hardware and requires more time to expand capacity.
Here’s a quick side-by-side comparison of key performance metrics:
Performance Metrics Table
| Performance Metric | On-Premise AI | Cloud AI |
|---|---|---|
| Typical Latency | <100 ms to 150 ms | 200 ms to 800 ms |
| Throughput (Llama 3.1 70B) | ~80 to 280 tokens/sec | Variable by tier/rate limits |
| Scalability | Limited by hardware | Elastic; near-instant scaling |
| Deployment Speed | Weeks to months (hardware setup) | Minutes (on-demand) |
| GPU Utilization | Customer-managed (10–40%) | Provider-managed (60–85%) |
| Network Dependency | Low (internal LAN/InfiniBand) | High (public internet/WAN) |
For workloads exceeding 1 billion tokens per month with strict latency requirements under 150 ms, on-premise AI is often the better choice. However, if your workload is unpredictable or you need immediate access to cutting-edge GPUs without worrying about maintenance, cloud AI’s elastic scalability might be the way to go.
When to Choose Cloud AI
Cloud AI is a smart choice for workloads that don’t exceed 1 billion tokens per month or require less than 6 hours of daily processing. In such cases, investing in specialized hardware often doesn’t make financial sense. With its pay-as-you-go model, Cloud AI eliminates the need for hefty upfront investments. For example, a single NVIDIA H100 GPU can cost between $30,000 and $40,000 – and that’s before factoring in servers, cooling systems, or data center space. Instead, you only pay for what you use, making it perfect for fluctuating demand or when you’re still experimenting with various AI models. This flexibility makes Cloud AI a strong contender when agility and operational efficiency are key priorities.
Best Use Cases for Cloud AI
Cloud AI shines in several specific scenarios:
- Unpredictable demand patterns: Think of retail apps during Black Friday or tax software during the filing season. The elastic scaling capabilities of Cloud AI ensure there’s no idle capacity or performance bottlenecks during unexpected surges in demand.
- Development and testing environments: Teams can quickly access a variety of GPU configurations without enduring long procurement timelines for hardware.
- Low-utilization workloads: For systems that remain idle most of the day, on-premise infrastructure only becomes cost-effective when utilization consistently hits 60–70% of what you’d spend on cloud services.
- Access to cutting-edge models: Models like GPT-4.1, Claude 3.5, or Gemini 1.5 Pro often outperform open-source alternatives by 6–12 months and are immediately available via cloud APIs.
For instance, in May 2025, Allied Banking Corporation in Hong Kong transitioned its operations to the cloud using Finastra‘s Essence solution. This move allowed the bank to scale cost-effectively and improve retail analytics without the hassle of maintaining physical infrastructure. Similarly, Cognizant collaborated with Google Cloud in 2025 to implement generative AI through Vertex AI, enhancing healthcare administrative processes and patient engagement – all without the need to build internal GPU clusters.
"Cost management isn’t a barrier; it’s an enabler. It allows you to experiment, innovate, and build AI solutions in a responsible way."
- Pathik Sharma, Cloud FinOps Lead, Google Cloud Consulting
How Cloud AI Reduces Costs
Cloud AI doesn’t just offer flexibility – it can also significantly cut costs through strategic resource management. For example:
- Spot instances and interruptible VMs: These options can reduce compute costs by up to 90% for tasks like model training or batch processing.
- AWS Savings Plans: These plans offer up to 72% savings compared to standard on-demand pricing.
- Serverless AI inference: By scaling infrastructure to zero during idle periods, serverless inference can lower costs by as much as 80% compared to static deployments.
A 3-year total cost analysis comparing a 4× NVIDIA A100 GPU workload showed that cloud solutions were 50.3% cheaper than on-premise setups – $122,478 versus $246,624. The savings came from avoiding upfront hardware costs, maintenance staff, and facility expenses. For workloads involving fewer than 1 million inferences per month, cloud AI consistently proves to be the more economical option.
As of January 2026, pricing for cloud AI services continues to drop. For example, blended rates range from $3.13 per million tokens for Gemini 1.5 Pro to $20.00 for GPT-4 Turbo. These ongoing reductions make cloud AI increasingly attractive for organizations seeking flexibility without the burden of hardware ownership.
sbb-itb-8421839
When to Choose On-Premise AI
On-premise AI becomes a smart financial move when your infrastructure expenses hit around 60–70% of what you’d spend on cloud services. This setup is particularly effective for organizations with steady, high-volume usage. While cloud costs grow with every token processed, on-premise systems involve a fixed upfront investment that pays off when usage is consistent and predictable. Businesses running at high utilization rates (70–90% capacity) often find on-premise solutions more economical, whereas sporadic or experimental workloads are better suited for the cloud.
Best Use Cases for On-Premise AI
On-premise AI shines in three key scenarios.
First, industries like healthcare, finance, and government often have strict data residency rules under frameworks such as HIPAA or GDPR. These regulations require organizations to keep sensitive data fully under their control. For such industries, predictable, high-volume workloads make on-premise setups both practical and cost-efficient, especially when utilization exceeds 60–70%. Additionally, on-premise systems give businesses more flexibility to manage technical debt. For instance, they can switch between open-source models like Llama or Mistral without being tied to a specific cloud provider’s ecosystem.
Second, latency-sensitive applications see a major advantage with on-premise infrastructure. When every millisecond counts – think high-frequency trading, autonomous systems, or real-time fraud detection – on-premise setups can deliver 2–5× lower latency than cloud APIs. For example, response times can drop below 100ms with on-premise systems, compared to 200–800ms in the cloud. A global bank, for instance, deployed an on-premise chatbot and fraud detection system powered by 16 NVIDIA H100 GPUs. This system processed 25 billion tokens monthly, achieving a latency of under 50ms (compared to 300ms in the cloud) and saving $97,000 per month.
"Running their AI services on-premises has turned out to be anywhere from a third to one-fifth of the cost of cloud-based options."
- Chris Wolf, Global Head of AI and Advanced Services, VMware Cloud Foundation Division, Broadcom
These examples highlight how on-premise setups offer not just cost savings but also strategic advantages in specific scenarios.
Long-Term Cost Benefits of On-Premise AI
The financial benefits of on-premise AI only grow over time. For a mid-size company processing 10 billion tokens monthly, a 3-year cost analysis shows $1.43 million for an on-premise setup versus $3.33 million for the cloud – resulting in a 57% cost reduction. A high-performance 8 NVIDIA H100 GPU cluster typically breaks even in about 11.9 months compared to cloud on-demand pricing. After reaching this breakeven point, every additional month translates to direct savings.
Hardware costs are also expected to drop, with GPU prices predicted to decline by 15–20% annually as supply improves by 2026. Operational expenses, such as power, cooling, and staffing, usually account for 20–35% of the initial investment. These costs remain steady regardless of workload fluctuations, often yielding a payback period of 6 to 18 months.
At scale, the cost advantage becomes even more striking. While cloud APIs like Claude 3.5 Sonnet charge $9 per million tokens, on-premise per-inference costs can be 40–60% lower when processing billions of tokens each month. Dropbox, for example, transitioned its core storage and related workloads to on-premise infrastructure, saving $75 million over two years.
Hybrid Approach: Mixing Cloud and On-Premise AI
By blending cloud and on-premise AI, organizations can strategically manage workloads to maximize efficiency and minimize costs. This hybrid approach allows businesses to allocate specific tasks to the most cost-effective platform. For instance, high-volume, predictable tasks are handled on-premise, ensuring optimal use of existing hardware. Meanwhile, the cloud steps in for traffic surges or experimental projects, offering the flexibility needed to adapt quickly. This model combines fixed on-premise costs with the scalability of the cloud, creating a balance between performance and cost savings.
How Hybrid AI Works
Hybrid AI systems use intelligent routing to direct workloads based on their nature and requirements. A great example comes from 2025, when a digital payments platform adopted this approach. By routing 70% of its traffic locally, 25% to edge ML inference, and only 5% to the cloud, the company slashed its monthly costs from $41,328 to $7,911. Latency also improved dramatically, dropping from 280 ms to just 85 ms.
Another case involves a European logistics company that implemented a hybrid setup across 18 distribution centers in Q3 2025. They used NVIDIA Jetson AGX Orin units for local package sorting, while the cloud handled more complex optimization tasks. This setup cut monthly costs by 52%, from $14,200 to $6,800, and reduced latency from 220 ms to 70 ms. The $35,982 hardware investment paid off in under five months. These examples highlight how hybrid AI not only reduces costs but also enhances performance, paving the way for even greater efficiency.
Cost and Performance Gains from Hybrid AI
For workloads like processing 12 billion tokens per month, a hybrid model can deliver significant savings. Routing 10 billion tokens on-premise and 2 billion through the cloud reduces monthly costs to about $63,000 – a 42% cut compared to a fully cloud-based solution. Over a five-year period, hybrid deployments can achieve a 44% lower total cost of ownership. Additionally, migrating to a hybrid environment is 57% cheaper and requires 59% less staff time than transitioning to a fully cloud-based infrastructure.
Performance gains are equally compelling. By processing most requests locally, hybrid setups can reduce latency by up to 68%. It’s no surprise that around 80% of mature AI deployments eventually adopt this model, as it strikes a balance between cost-efficiency and operational reliability. Unlike pure cloud systems, hybrid configurations ensure critical functions remain operational even during internet outages – a crucial advantage.
Here’s a breakdown of the monthly cost benefits of hybrid AI compared to other deployment models:
Hybrid AI Cost Comparison Table
| Configuration | Monthly Cost | Savings vs. Pure Cloud |
|---|---|---|
| Pure Cloud API | $108,000 | 0% |
| Hybrid (10B On-Prem / 2B Cloud) | $63,000 | 42% |
| Pure On-Premise (Amortized) | $45,000 | 58% |
Based on a workload of 12 billion tokens per month
Conclusion
Cloud AI is ideal for handling fluctuating workloads under 1 billion tokens per month, offering a pay-as-you-go model that keeps upfront costs low. It also provides instant access to advanced models like GPT-4 and Claude 3.5. However, API latency typically ranges between 200 ms and 800 ms, and costs can rise significantly with increased usage.
On the other hand, on-premise infrastructure shines when processing consistently high volumes – over 5 billion tokens per month. In such cases, organizations can cut costs by 40-60% per inference. That said, the initial investment is steep, ranging from $300,000 to $500,000, with ongoing expenses for hardware maintenance, power, and cooling .
A hybrid approach offers a smart middle ground. By directing predictable traffic to on-premise servers while using cloud services for overflow, companies can reduce costs by approximately 52% and lower latency by up to 68%.
For businesses starting out, cloud APIs are a great way to test and validate usage. But if your demand consistently exceeds 1 billion tokens per month, it’s worth conducting a 3-year total cost of ownership (TCO) analysis. This should include hardware depreciation, power costs (around $8,700 annually for an 8× H100 cluster at $0.10 per kWh), and staffing. If achieving sub-100 ms latency or maintaining full control over data for compliance is critical, on-premise will always be the better option, regardless of scale. These guidelines help ensure that your organization strikes the right balance between cost and performance.
FAQs
How do I decide between Cloud AI and On-Premise AI for my needs?
When deciding between Cloud AI and On-Premise AI, it’s important to weigh factors like costs and usage patterns. Cloud AI operates on a pay-as-you-go basis, making it a flexible choice for businesses with fluctuating or smaller workloads. In contrast, On-Premise AI demands a hefty upfront hardware investment but can be more economical over time for organizations with consistent, high-demand workloads.
Another key consideration is performance and latency. On-premise solutions tend to deliver faster response times, which is crucial for tasks like real-time processing. Cloud platforms, while slightly slower due to network communication, offer the advantage of always having access to the latest hardware without the hassle of maintenance.
Lastly, think about security and compliance. On-premise systems keep your data in-house, which can simplify meeting regulatory standards. Meanwhile, cloud providers offer strong built-in security measures, but data transfers across regions might complicate compliance for certain industries. Your choice should ultimately align with your workload needs, budget constraints, and operational goals.
How can a hybrid AI solution reduce costs while improving performance?
A hybrid AI solution blends the advantages of on-premise hardware with cloud platforms to achieve an ideal mix of cost efficiency and performance. Routine AI tasks can run on affordable on-premise systems, while the cloud is tapped into during high-demand periods. This setup can reduce expenses by 60-80%, all while maintaining the speed and low latency needed for critical workloads.
This model is especially useful for businesses that require flexible AI resources but want to avoid the ongoing expenses of an entirely cloud-based system. It offers a practical way to balance cost and performance, making it a smart choice for handling dynamic workloads.
What are the long-term cost advantages of using on-premise AI instead of cloud-based AI?
On-premise AI offers a way to cut long-term costs by removing the need for recurring cloud fees, which often include charges for usage and data processing. With on-premise setups, you’re looking at fixed hardware expenses that can be spread out over time, making this option far more budget-friendly for businesses handling high volumes – think tens of millions of queries each month.
What’s more, on-premise systems usually provide lower costs per inference at scale, often reducing expenses by 40–60% compared to cloud-based alternatives. For organizations managing large-scale AI workloads, this setup not only ensures financial consistency but also delivers notable savings over time.